Archivos .md para inteligencia artificial y control de tokens
Los archivos .md se están convirtiendo en una pieza clave para trabajar con inteligencia artificial porque permiten transformar documentos en conocimiento limpio, estructurado y fácil de procesar. Al organizar la información con títulos, listas, tablas y metadatos, ayudan a mejorar el chunking, reducir ruido y controlar el consumo de tokens. En un entorno con agentes, RAG y LLMOps, Markdown facilita una IA más precisa, eficiente y sostenible.
Durante años hemos tratado los documentos como si solo tuvieran que cumplir una función: ser leídos por personas. Un informe en PDF, una propuesta en Word, una guía en Google Docs, una tabla en Excel o una presentación en PowerPoint eran suficientes si alguien podía abrirlos, revisarlos, comentarlos o compartirlos.
Pero la inteligencia artificial ha cambiado esa lógica.
Ahora los documentos también los leen modelos de lenguaje, agentes autónomos, copilotos internos, sistemas RAG y asistentes personalizados. Y cuando una IA trabaja con documentos, el formato deja de ser un detalle menor. Se convierte en una parte crítica del rendimiento, la precisión y el coste.
No es lo mismo darle a una IA un PDF pesado, con columnas, imágenes incrustadas y saltos extraños, que entregarle un archivo limpio, estructurado y fácil de interpretar. No es lo mismo alimentar un agente con un Word convertido de cualquier manera, que proporcionarle un documento preparado con títulos, secciones, listas, tablas y metadatos útiles.
Aquí es donde entran los archivos .md.
Markdown, durante años asociado a desarrolladores y documentación técnica, empieza a convertirse en una pieza clave para trabajar con inteligencia artificial. No porque sea sofisticado, sino precisamente porque es simple: texto plano, estructura clara, buena legibilidad y muy poco ruido.
Y esto conecta con otro concepto que cada vez será más importante: la tokenomía. Si los modelos consumen tokens para leer, interpretar y responder, entonces cada documento que usamos como contexto tiene un coste. Un documento mal preparado no solo complica la respuesta. También puede encarecerla.
En este post vamos a ver por qué los archivos .md pueden convertirse en una herramienta clave para preparar conocimiento empresarial más limpio, más estructurado y más eficiente para la IA.
Qué son los archivos .md y por qué empiezan a importar
Un archivo .md es un documento escrito en Markdown, un lenguaje de marcado ligero que permite estructurar texto sin convertirlo en un formato pesado. Dicho de forma sencilla: es texto plano con señales de organización.
Un título se escribe con una almohadilla:
# Título principal
Un subtítulo con dos:
## Subtítulo
Una lista con guiones:
– Primer punto
– Segundo punto
– Tercer punto
La clave de Markdown no está solo en que sea fácil de leer. Está en que ese marcado le dice a la IA cómo está organizado el contenido.
Un encabezado no es decoración. Es una señal. Le indica al sistema que empieza una nueva sección, que hay una jerarquía y que unas ideas pertenecen a un bloque concreto. Esto es fundamental cuando usamos documentos largos en sistemas RAG, agentes o bases de conocimiento.
Una IA normalmente no carga todo un documento largo en cada consulta. Lo divide en fragmentos, o chunks, para recuperar solo las partes relevantes. Si el documento no está bien estructurado, el sistema puede cortar el texto por tamaño: las primeras 500 palabras, luego las siguientes 500 y así sucesivamente. Ese enfoque puede partir una idea por la mitad, separar una lista de su título o dejar una tabla sin el contexto que le da sentido.
Con Markdown, el particionado puede ser más inteligente. Los encabezados #, ## y ### permiten dividir el documento por bloques semánticos, no solo por número de palabras. Si una sección se llama “Criterios de registro de oportunidades”, el sistema puede mantener unidos los párrafos, listas y ejemplos que pertenecen a esa sección.
Por eso el marcado importa. Es la forma de decirle a la IA: esto es un título, esto es una subsección, esto es una lista, esto es una tabla, esto es código, esto es una cita.
Cuanto más clara es esa estructura, más fácil resulta recuperar, interpretar y reutilizar el conocimiento.
Markdown como idioma operativo de la inteligencia artificial
Durante mucho tiempo Markdown se ha visto como un formato técnico. Algo propio de desarrolladores, repositorios de GitHub, documentación de software o archivos README.
Pero con la inteligencia artificial está ocurriendo algo interesante: Markdown está dejando de ser solo un formato de documentación para convertirse en un idioma operativo entre personas, modelos de lenguaje y agentes autónomos.
Un agente de IA necesita instrucciones. Necesita saber qué puede hacer, cuándo debe actuar, qué pasos debe seguir, qué restricciones debe respetar y qué información debe consultar. Todo eso no puede vivir únicamente en conversaciones improvisadas o prompts sueltos. A medida que los agentes se vuelven más útiles, también necesitan una documentación más clara, estable y reutilizable.
Ahí los archivos .md encajan muy bien.
Un archivo Markdown puede actuar como una guía de comportamiento para un agente, como una memoria de proyecto, como una ficha de habilidad, como una base de conocimiento o como un procedimiento operativo. Puede definir una metodología, describir reglas de negocio, explicar un flujo de trabajo o establecer cómo debe responder un asistente en determinados casos.
Por eso están apareciendo convenciones como AGENTS.md, SKILL.md, CLAUDE.md o GEMINI.md. Más allá del nombre concreto, la idea de fondo es la misma: usar Markdown para documentar instrucciones que los sistemas de IA puedan leer y aplicar.
Esto supone un cambio importante. Antes escribíamos documentación para que una persona aprendiera a hacer algo. Ahora empezamos a escribir documentación para que una IA pueda ayudar a hacerlo, guiarlo, automatizarlo o ejecutarlo parcialmente.
Y eso exige otra forma de pensar.
Una instrucción para un agente no debería ser ambigua. Debería indicar con claridad cuándo se aplica, qué entrada espera, qué salida debe generar, qué límites debe respetar y cuándo debe pedir validación humana.
Markdown facilita ese tipo de escritura porque obliga a ordenar. No maquilla el desorden con diseño visual. Si una instrucción está mal pensada, se nota. Si está bien estructurada, también.
La nueva documentación para IA no va de acumular información. Va de convertirla en conocimiento operativo.
Del documento bonito al conocimiento procesable
Durante años hemos valorado los documentos por cómo se ven. Una portada cuidada, una buena maquetación, tablas agradables, imágenes bien colocadas y una tipografía coherente transmiten profesionalidad. Y eso sigue siendo importante cuando el documento tiene una función de comunicación, presentación, venta o entrega final.
Pero cuando hablamos de inteligencia artificial, aparece otra pregunta: ¿ese documento es procesable?
Un documento puede ser perfecto para una persona y, al mismo tiempo, incómodo para una IA. Un PDF bien diseñado puede esconder problemas de extracción. Una tabla visualmente clara puede romperse al convertirse en texto. Un título con buen aspecto puede perder su jerarquía si no está correctamente marcado. Una página con columnas puede mezclarse en el orden de lectura.
Markdown juega en otra liga. No intenta reproducir la apariencia visual del documento. Se centra en conservar lo que realmente importa para la IA: estructura, jerarquía y significado.
Eso no significa que Word, PDF o PowerPoint desaparezcan. Cada formato tiene su función. El PDF puede seguir siendo perfecto para una propuesta final. Word puede ser cómodo para edición colaborativa. PowerPoint seguirá siendo útil para comunicar visualmente.
Pero cuando el objetivo es alimentar un sistema RAG, un agente, un copiloto interno o una base de conocimiento, necesitamos documentos preparados para trabajar.
Un procedimiento comercial en PDF puede ser útil para formar a una persona. Ese mismo procedimiento convertido en Markdown limpio puede alimentar un asistente, orientar un agente de CRM o integrarse en una base de conocimiento. La diferencia está en pasar de documentación estática a conocimiento activable.
Esta es una de las ideas centrales del cambio: la documentación ya no solo describe cómo trabaja la empresa. Empieza a formar parte de cómo trabaja la IA dentro de la empresa. Y ahí el formato importa.
La tokenomía cambia las reglas del juego
Hasta ahora muchas empresas han usado inteligencia artificial con una sensación parecida a encender una luz: haces una pregunta, obtienes una respuesta y sigues trabajando. Parece simple, inmediato y casi invisible. Pero por debajo pasan muchas cosas.
Cada instrucción enviada a un modelo se transforma en tokens. Cada documento usado como contexto también se transforma en tokens. Cada respuesta generada consume tokens. Y en muchos servicios de IA, esos tokens tienen un coste directo o indirecto.
Por eso empieza a tener sentido hablar de tokenomía: la gestión inteligente del consumo de tokens. No es un concepto solo técnico. Es una cuestión de negocio. Si una empresa empieza a usar IA en procesos reales, con agentes, copilotos, documentación interna, automatizaciones y bases de conocimiento, necesita saber cuánto consume, dónde consume y por qué consume.
La tokenomía no consiste en gastar lo mínimo posible. Esa sería una visión pobre. Consiste en obtener el máximo valor de cada token consumido.
A veces necesitaremos más contexto. A veces necesitaremos un modelo más potente. A veces será razonable pagar más por una respuesta de mayor calidad. Pero eso debe ser una decisión consciente, no una consecuencia accidental de documentos mal preparados, agentes sin límites o modelos sobredimensionados.
Aquí los archivos .md aportan una ventaja importante: ayudan a reducir el coste del desorden. Al trabajar con documentos más claros y estructurados, la IA puede recuperar mejor la información que necesita y evitar cargar contenido innecesario.
La pregunta ya no es solo “¿responde bien la IA?”. La pregunta empieza a ser más completa: ¿cuánto cuesta esa respuesta, qué contexto ha utilizado, qué modelo ha intervenido y si había una forma más eficiente de llegar al mismo resultado? Esa es la conversación que muchas empresas tendrán que empezar a tener.
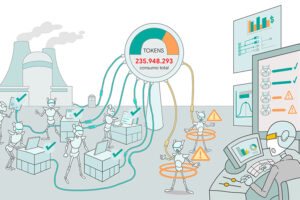
El caso CRM Copilot y el consumo invisible de tokens
Este ejemplo nace de un proyecto personal muy concreto: un CRM Copilot diseñado para resolver uno de los problemas más persistentes en cualquier implantación de CRM. Después de más de 20 años implantando CRMs, hay una conclusión que se repite una y otra vez: el problema no suele estar solo en la herramienta. El problema está en el uso. Y, más concretamente, en que el usuario no registra la información. El CRM puede estar perfectamente configurado. Puede tener buenos módulos, buenos campos, buenos embudos, buenas automatizaciones y buenos informes. Pero si el equipo comercial no registra llamadas, reuniones, oportunidades, contactos, empresas, tareas o próximos pasos, el sistema empieza a perder valor.
Y esto no ocurre porque el usuario sea descuidado. Muchas veces ocurre porque registrar información es pesado, interrumpe el trabajo comercial y compite con la actividad diaria. El comercial habla con clientes, responde correos, prepara propuestas, atiende reuniones y avanza oportunidades. Después, además, tiene que entrar en el CRM y documentarlo todo.
La idea del CRM Copilot es atacar precisamente ese punto. En lugar de pedirle al usuario que registre manualmente toda la información, el agente ayuda a buscar, interpretar y registrar lo importante. Para hacerlo, he creado una estructura de archivos .md por módulo: contactos, empresas, oportunidades y otros bloques funcionales del CRM. Cada archivo Markdown define el contexto, las reglas, los criterios y la lógica de trabajo de cada módulo. Cuando el agente trabaja sobre contactos, usa el contexto de contactos. Cuando trabaja sobre empresas, usa el contexto de empresas. Cuando trabaja sobre oportunidades, interpreta la información desde la lógica comercial correspondiente.
Con los conectores adecuados, el agente puede revisar información, entender qué ha pasado, extraer datos relevantes y registrar aquello que el usuario normalmente tendría que introducir a mano. El objetivo es claro: reducir fricción y conseguir que el CRM esté vivo sin convertir al equipo comercial en administrativo de su propia actividad.
El enfoque es muy potente, pero abre otro problema: el consumo de tokens se dispara. Y aquí aparece la parte compleja. No siempre es evidente dónde se produce ese consumo. Puede estar en los conectores, en la carga de contexto, en archivos .md demasiado largos, en instrucciones repetidas, en el modelo utilizado o en pasos internos del agente que no quedan suficientemente visibles. El usuario pide una tarea y el agente la hace. Pero no siempre se ve con claridad todo lo que ha ocurrido por debajo.
Este caso conecta muy bien con la tokenomía porque demuestra dos cosas al mismo tiempo. La primera: la IA puede resolver uno de los grandes bloqueos históricos del CRM. La segunda: si no se gobierna bien, el coste puede crecer más rápido que el valor percibido.
LLMOps para controlar costes, calidad y rendimiento
Cuando una empresa empieza a usar inteligencia artificial de forma puntual, casi todo parece sencillo. Un usuario pregunta, el modelo responde. Un equipo prueba un asistente, obtiene resultados interesantes. Alguien crea un prompt, automatiza una tarea y gana tiempo. Pero cuando la IA entra en procesos reales, la situación cambia.
Ya no hablamos de una conversación aislada. Hablamos de agentes conectados a herramientas, documentos usados como contexto, bases de conocimiento, modelos diferentes, usuarios con distintos permisos, automatizaciones recurrentes y consumo de tokens. Ahí aparece la necesidad de LLMOps.
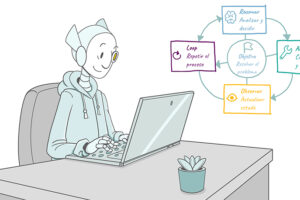
LLMOps es la disciplina que permite operar sistemas basados en modelos de lenguaje con control, calidad y eficiencia. Dicho de forma sencilla: es la capa que evita que la IA se convierta en una caja negra difícil de gobernar. Podemos entender LLMOps en tres grandes bloques.
- El primero es la observabilidad. Saber qué ocurre: qué agentes consumen más, qué usuarios generan más uso, qué procesos cargan más contexto, qué modelos intervienen y dónde aparecen errores o consumos anómalos.
- El segundo es el gobierno. Definir reglas claras: qué modelos se usan para cada tarea, qué límites de consumo existen, cuándo debe intervenir una persona, qué documentos pueden usarse como contexto y cómo se actualizan las instrucciones.
- El tercero es la optimización. Mejorar la relación entre coste, velocidad y calidad. No se trata de gastar menos por sistema, sino de conseguir mejores resultados con una arquitectura más inteligente. Aquí los archivos .md tienen un papel práctico. Muchas reglas de uso, instrucciones de agentes, políticas internas, criterios de escalado, documentación de conectores y procedimientos de revisión pueden mantenerse en Markdown. Así se pueden versionar, revisar y reutilizar como contexto operativo.
En una organización madura, la documentación no solo describe el sistema. También ayuda a gobernarlo. La inteligencia artificial no escala bien solo con entusiasmo. Escala bien con método.
Cómo debe ser un archivo .md optimizado para IA
Convertir un documento a Markdown no consiste en cambiar una extensión. Un .docx, un .pdf o incluso un .md mal generado pueden seguir arrastrando mucho ruido documental. Y ese ruido, cuando entra en un sistema de IA, se paga en tokens, precisión y tiempo de procesamiento. Un archivo .md optimizado para IA debe cumplir una idea básica: ser legible para una persona y procesable para una máquina.
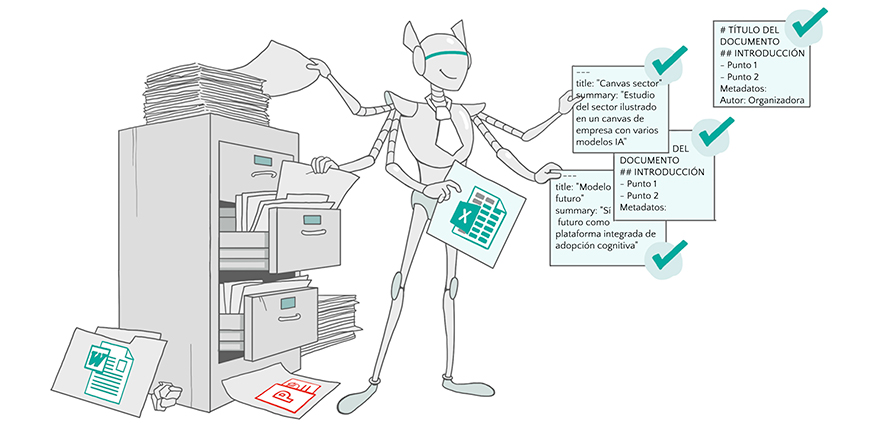
Lo primero es contar, cuando tenga sentido, con un bloque YAML de metadatos al inicio del documento. Este bloque puede describir el título, el resumen, la versión, el área responsable o los encabezados principales.
Por ejemplo:
—
title: «Procedimiento comercial para gestión de oportunidades»
summary: «Guía operativa para registrar, actualizar y analizar oportunidades comerciales con apoyo de IA.»
version: «1.0»
area: «comercial»
headings:
– «Objetivo»
– «Criterios de registro»
– «Campos obligatorios»
– «Próximos pasos»
—
Este bloque no está ahí para decorar. Ayuda a clasificar, recuperar y contextualizar el documento. En una base de conocimiento, esos metadatos pueden ayudar a decidir cuándo debe cargarse ese archivo, a qué proceso pertenece o qué tipo de información contiene. Después viene la estructura del contenido. Un único # H1 para el título principal, secciones ## H2 para los bloques importantes y ### H3 para los apartados internos. Esta jerarquía facilita que el documento pueda dividirse por ideas completas, no solo por tamaño. También hay que cuidar las listas, las tablas y los enlaces. Una lista bien escrita representa pasos, requisitos o criterios. Una tabla bien reconstruida conserva relaciones entre datos. Un enlace válido aporta contexto. Un enlace roto solo añade ruido.
Y hay que limpiar lo que no aporta: imágenes locales que no se pueden recuperar, bloques Base64, anclas internas heredadas, HTML residual, comentarios invisibles, saltos duplicados, espacios extraños o referencias a archivos que ya no existen. El resultado debe ser un Markdown limpio, en UTF-8, con estructura clara y sin elementos innecesarios.
La pregunta ya no es “¿puedo convertir este documento a Markdown?”. La pregunta buena es: ¿puedo convertir este documento en conocimiento operativo para IA?
Con qué herramientas podemos gestionar archivos .md
Una de las ventajas de los archivos .md es que no obligan a trabajar con herramientas complejas. Markdown es texto plano, así que puede crearse con un editor sencillo, mantenerse en una carpeta, versionarse en un repositorio o usarse como base de conocimiento para un sistema de IA. Ahora bien, en una empresa no siempre tiene sentido pedirle a todo el equipo que trabaje directamente en un editor técnico. Muchos perfiles se sienten más cómodos redactando en una herramienta visual, colaborativa y conocida. Por eso, una recomendación práctica es empezar con una aplicación ligera como Google Docs. Google Docs permite escribir, revisar y comentar de forma cómoda. Si se usa con criterio, puede generar documentos bastante limpios: títulos reales, listas sencillas, tablas no excesivamente complejas y poco formato visual innecesario.
El flujo puede ser simple:
- Redactar el contenido en Google Docs o en una herramienta ligera.
- Usar estilos reales para los títulos, no solo negritas grandes.
- Mantener listas, tablas y secciones lo más limpias posible.
- Convertir el documento a Markdown.
- Optimizar el archivo .md antes de usarlo como contexto para IA.
Para la conversión, una herramienta especialmente interesante es MarkItDown, de Microsoft. Permite convertir distintos formatos de archivo a Markdown, como documentos de Office, PDFs, páginas HTML o contenido estructurado. Encaja muy bien con esta nueva necesidad: transformar documentos tradicionales en material más legible y procesable por modelos de lenguaje. También podemos crear y editar Markdown directamente con herramientas como Visual Studio Code, Obsidian, Typora, MarkText, Zettlr o HackMD. Visual Studio Code es útil si queremos control de versiones y revisión del marcado. Obsidian funciona muy bien para bases de conocimiento y notas conectadas. Typora resulta cómodo para quien prefiere una escritura más visual. HackMD puede ayudar cuando necesitamos colaboración online.
Para visualizar archivos .md, GitHub y GitLab los renderizan automáticamente. También se pueden previsualizar en Visual Studio Code, Obsidian, Typora o editores online. Y si queremos publicar documentación completa, herramientas como MkDocs, Docusaurus, VitePress o GitBook permiten convertir carpetas de Markdown en sitios web navegables.
Ahora bien, convertir no es suficiente. Por eso he diseñado un prompt que permite optimizar documentos de cualquier tipología y convertirlos en archivos .md limpios, estructurados y preparados para inteligencia artificial. Sirve para trabajar con .docx, .pdf, .txt, .html o incluso con archivos .md que ya existen pero están mal generados.
Aquí tienes el prompt para hacer la prueba:
P123-Conversor-Markdown-valido.md
La idea no es complicar el trabajo documental. Es justo lo contrario: crear un proceso sencillo para pasar de documentos pensados solo para personas a conocimiento preparado para personas, agentes y sistemas de inteligencia artificial.
Qué deberían empezar a hacer las empresas
La adopción de archivos .md no debería obligar a cambiar de aplicación ni a complicar el trabajo del equipo. Si la empresa ya redacta en Google Docs o en Word, puede seguir haciéndolo. La diferencia está en marcar mejor el contenido desde el origen y optimizarlo después para que pueda trabajar bien con IA.
- El primer paso es identificar qué documentación merece la pena preparar: procedimientos, guías internas, documentación de servicios, manuales de soporte, prompts reutilizables, preguntas frecuentes o políticas de uso. No todo tiene que convertirse a Markdown, solo aquello que pueda alimentar agentes, asistentes o bases de conocimiento.
- El segundo paso es marcar bien los datos en la aplicación que ya se utiliza. Si trabajamos en Word, hay que aplicar los estilos correctos: título, subtítulo, encabezado 1, encabezado 2, listas numeradas, viñetas y tablas bien formadas. Si trabajamos en Google Docs, lo mismo: usar estilos de título reales, listas reales y estructuras limpias. No vale simular un titular con una frase en negrita y tamaño grande. Para una persona puede parecer un encabezado, pero para una conversión posterior puede ser solo texto con formato.
- El tercer paso es separar los documentos en unidades más pequeñas y útiles. La empresa tradicional tiende a crear documentos enormes: “manual completo”, “procedimiento general”, “guía definitiva”, “documentación global”. Para una IA, muchas veces eso no es lo más eficiente. Es mejor trabajar con piezas temáticas, bien nombradas y fáciles de localizar. Así el sistema puede cargar el contexto adecuado sin arrastrar información innecesaria.
- El cuarto paso es limpiar antes de conectar. Este punto es crítico. No deberíamos conectar una carpeta llena de PDFs antiguos, documentos duplicados, versiones contradictorias y archivos desactualizados esperando que la IA lo arregle todo. La IA puede ayudar a ordenar, pero si el contexto de partida es confuso, el riesgo de respuestas incorrectas aumenta.
- El quinto paso es aplicar el P123, el prompt para optimizar documentos y convertirlos en archivos .md más limpios, estructurados y preparados para inteligencia artificial. La conversión por sí sola no siempre basta. El P123 ayuda a revisar el resultado, eliminar ruido, reconstruir estructura, conservar lo importante y generar un Markdown más útil para agentes, asistentes o sistemas RAG.
- El sexto paso es probar con documentos reales. Mejor empezar con unos pocos archivos importantes y comprobar si el resultado mejora la recuperación, reduce ambigüedad y facilita mejores respuestas en un asistente, un agente o una base de conocimiento.
- El séptimo paso es medir. Si hablamos de tokenomía, necesitamos observar qué documentos se consultan, cuánto contexto cargan, qué agentes consumen más y qué tareas obligan a usar modelos más avanzados.
- El octavo paso es formar al equipo en lo básico. No para convertir a todo el mundo en técnico, sino para que entiendan por qué un título bien marcado, una tabla simple o un documento menos recargado pueden mejorar el trabajo de la IA.
- La idea es sencilla: seguir trabajando con herramientas conocidas, pero generar documentos más limpios, convertirlos a archivos .md y optimizarlos antes de conectarlos a sistemas inteligentes.
Conclusión
La inteligencia artificial está entrando en una etapa más madura. La fase de probar herramientas, sorprenderse con las respuestas y experimentar con prompts sigue siendo útil, pero ya no es suficiente. Cuando una organización conecta IA con procesos reales, aparece otra conversación: cómo se gobierna, cómo se mide, cuánto cuesta, qué calidad entrega y con qué conocimiento trabaja. En esa conversación, los archivos .md tienen más importancia de la que parece. No son una solución mágica ni sustituyen a Word, PDF, Excel o PowerPoint. Pero empiezan a ocupar un espacio muy concreto: el de la documentación operativa para IA. Documentos que no solo se leen, sino que se recuperan, se fragmentan, se interpretan y, en algunos casos, guían el comportamiento de agentes.
La IA no convierte automáticamente el desorden en inteligencia. Si conectamos documentos confusos, duplicados o desactualizados, la IA puede amplificar ese desorden. Responderá con más seguridad, pero no necesariamente con más rigor. Por eso la tokenomía será cada vez más importante. No se trata de gastar menos por gastar menos. Se trata de entender dónde se genera valor y dónde se desperdicia capacidad.
Los archivos .md ayudan en ese punto. Permiten estructurar mejor, limpiar mejor, dividir mejor y gobernar mejor el conocimiento.
La ventaja competitiva no estará solo en tener acceso al modelo más potente. Estará en saber usarlo mejor: con buenos documentos, buenos criterios, buenos límites, buenas instrucciones y una arquitectura operativa bien pensada.
La próxima etapa no va solo de inteligencia artificial. Va de inteligencia organizativa. Y ahí, ordenar el conocimiento puede ser una de las decisiones más rentables.